難病の全ゲノム解析に欠かせないロングリードシーケンスについて、
研究開発担当者 荻 朋男氏に聞きました。

Q :ロングリードシーケンスとはどのような技術ですか?
A :全ゲノム解析の新しい技術です。これまでは、DNAを150塩基対程度の短い断片にして塩基配列を読み取り、それを重ね合わせて全ゲノムの配列を得る技術が主流でした(「解析の流れ」のページも参照)。これをショートリードシーケンスと呼びます。これに対して、ロングリードシーケンスでは、2万塩基対程度の長い断片の配列を読み取ります。ショートリードシーケンスでは、測定原理上、ゲノムのなかで読み取れない領域がありますが、ロングリードシーケンスでは断片をうまくつなぎ合わせれば、1本の染色体全体の塩基配列を得ることも可能です。
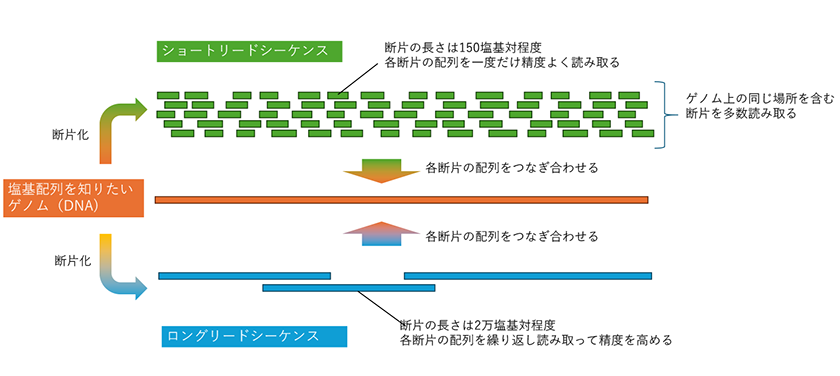
ショートリードシーケンスとロングリードシーケンスの違い(模式図)
Q :難病ゲノムの研究においてロングリードシーケンスが重要な理由を教えてください。
A :難病の原因となっている遺伝子の変異は、ショートリードシーケンスでは解析しにくいものが多いからです。
その1つは、決まった3塩基の並びが何十回も繰り返されている「トリプレットリピート」です。わかりやすい例で説明しましょう。ハンチントン病の患者さんの遺伝子中ではCAGという配列が繰り返されており、加齢につれてリピート回数が増えることや、リピート回数が多いほど症状が重くなることが知られています。しかし、ショートリードシーケンスでは、DNAを短い断片にして配列を読み取るため、リピート回数を正確に知ることは困難です。ロングリードシーケンスなら、リピート部分全体を含む長い領域を読み取るので、リピート回数が正確にわかり、リピート回数と病状の関係を詳しく調べたり、リピート回数を調節する薬を開発したりするのに役立ちます。
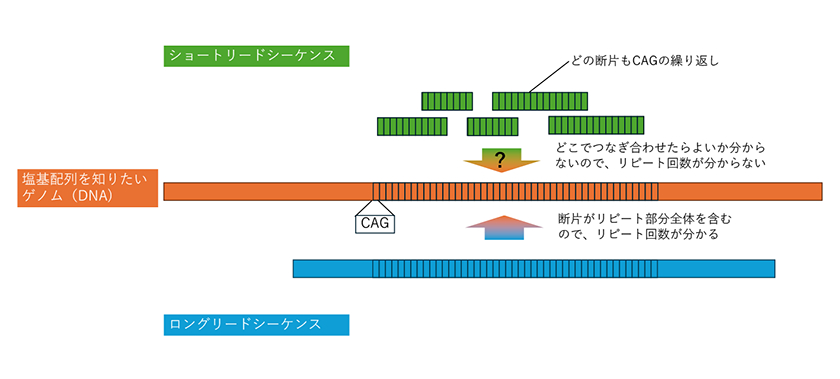
ロングリードシーケンスでは、リピート配列のリピート回数を正確に調べられる(概念図)
もう1つは、よく似た配列の遺伝子が2つある場合です。こちらも脊髄性筋萎縮症という有名な病気を例にとりましょう。この難病は、SMN1遺伝子に変異があって機能しないために起こります。それだけなら、この遺伝子の配列を調べれば診断できますが、問題は、この遺伝子の近くに配列がよく似たSMN2遺伝子があることです。SMN2遺伝子はSMN1遺伝子のバックアップ機能を持つ“偽遺伝子”ですが、ショートリードシーケンスでは、SMN1遺伝子とSMN2遺伝子を区別して配列を読み取ることが難しいのです。ロングリードシーケンスなら、両方の遺伝子を含む領域を解析できるので、SMN1遺伝子の変異を正しくとらえることができます。脊髄性筋萎縮症には治療薬があり、出生後できるだけ早い時期に投与すると顕著な効果があるのですが、これまでは遺伝子の検査に時間がかかることが早期投与の妨げとなっていました。ロングリードシーケンスを使えば出生後すぐに遺伝子レベルの確定診断ができますから、この問題の解決につながると期待されます。
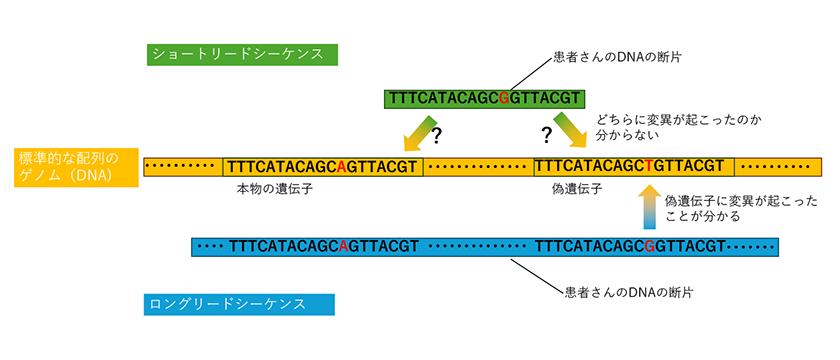
ロングリードシーケンスでは遺伝子と偽遺伝子を区別して配列を調べられる(概念図)
Q :本プロジェクトでは、ロングリードシーケンスをどのように利用していますか?
A :ロングリードシーケンスの装置にはいくつかの方式がありますが、本プロジェクトでは、2023年度にPacBio社の装置を4台名古屋大学に導入し、解析を産学連携企業に委託しています。全国の分担研究機関と協力医療機関から年間1000件程度の検体を受け入れて全ゲノム解析を行っており、その中から成果も出つつあります。
難病ゲノムの研究は、解析手法の進歩と共に進歩してきたといえます。染色体の顕微鏡観察から始まり、サンガーシーケンサー、マイクロアレイ、ショートリードの次世代シーケンサーなどの新しい手法が登場する度に、病気の原因が分かる患者さんの数が数%ずつ増えてきました。それでもまだ、50%ぐらいの患者さんは病気の原因が見つかっていない状況です。このため、本プロジェクトでは、ロングリードシーケンスの活用により、上でお話ししたような病態と変異の関係究明や確定診断のための研究だけでなく、まだ原因が分かっていない難病の原因究明に取り組んでいます。

ロングリードシーケンスと他の様々な手法の組合せで、難病の理解が進む
Q :ロングリードシーケンスを利用する上で難しいのはどういう点ですか?
A :ロングリードシーケンスでは、ゲノム全体の中の変異を精度よく抽出できますが、それだけで難病の原因究明が進むわけではないことです。
その理由の1つは、難病の患者さんの数が少ないことです。患者さんの数が多ければ、患者さんに共通する遺伝子の異常が病気の原因だろうと見当がつきますが、患者さんの数が少ないと、遺伝子の異常があってもそれが病気の原因かどうかがすぐには分かりません。
また、これまでに原因が分かった難病のほとんどは、遺伝子のうち、タンパク質のアミノ酸配列の情報をもつ「エクソン」という部分が変異し、遺伝子からつくられるタンパク質が変化している場合です。しかし、遺伝子のうちのエクソン以外の部分(「イントロン」と呼ばれます)や、ゲノムのうちでも遺伝子以外の部分の変異が、間接的にタンパク質の変化を招く場合もあります。こういう場合は、変異と病気の関係を突き止めるのがとても難しいのです。
さらに、ゲノムの変異としては、1000塩基対を超えるような大きな領域が失われたり(欠失)、一つの遺伝子が何回も繰り返されたり(コピー数バリアント:CNV)するような大規模なものもあります(「全ゲノム解析の意義」のページも参照)。ロングリードシーケンスでは、このような変異もとらえることができますが、このような変異と病気の関係も、解明は困難です。
Q :今後の展望をお聞かせください。
A :日本では、20年ぐらい前から大勢の研究者が継続的に難病とゲノムの関係を研究するプロジェクトを立ち上げてきており、研究面でも、患者さんへの還元という面でも、大きな成果を挙げてきました。そうした蓄積に加え、本プロジェクトには日本の難病研究の「プロ」が集結しています。この強みと、ロングリードシーケンスの利点を生かすことで、難病の原因の解明と、よりよい治療につながる研究を進めていければと思います。
難病の患者さんの数は非常に少ないのに、なぜこうした研究が必要なのかというご意見もありますが、難病の研究は一般の方にも役に立ちます。難病の患者さんには、神経の異常、早期老化、がんになりやすいといった特性が見られ、そうした特性を研究することは、多くの方がかかる病気の理解と治療につながるからです。また、日本人の全ゲノムデータを蓄積していくことは、ゲノム研究や医薬品開発において日本の競争力を高めるためにも重要です。
国民の皆様のご理解をいただきながら、ロングリードシーケンスを活用して本プロジェクトを発展させてきたいと思います。
(2025年10月インタビュー)






